إستخراج الميزات من النص. الجزء 1
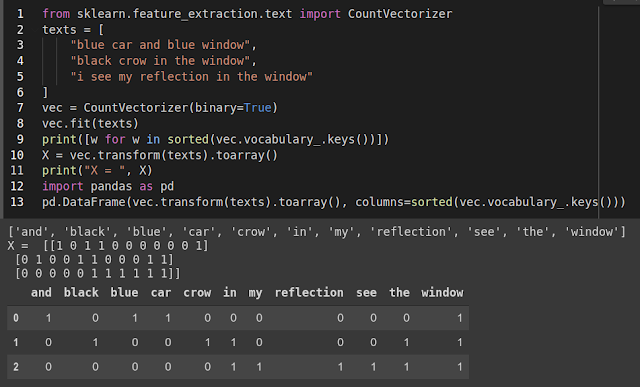
Text feature extraction في مجال تعلم الألة لايمكن إستعمال نص بشكله الخام كما هو! بل نحتاج إلى التعامل مع أرقام و لهذا نحن بحاجة إلى طريقة لتحويل النصوص إلى أرقام. هناك ثلاث عمليات أساسية و هي : (Tokenizing) تقطيع النص إلى مقاطع أساسية على حسب الفواصل التي نحددها مثل الفراغات التي بين الكلمات. (Counting ) حساب عدد مرات تكرار المقاطع الأساسية في النص. (normalizing) منح أوزان أو قيم للمقاطع الأساسية أو (Tokens). مكتبة (Scikit-Learn ) وفرت بعض الخوارزميات الجاهزة للتعامل مع النصوص و إستخراج الميزات منها. سوف نشرح جزءا منها في الجزء 1 و الباقي لاحقا إن شاء الله. 1- Binary Encoding : لنفرض أننا إختارنا (Tokens) عبارة عن كلمات. في هذه الطريقة نقوم بتحديد جميع الكلمات التى ظهرت في الداتا على شكل قائمة للمفردات. إذا كان عدد الكلمات (vocabulary list) هو 100 ألف فإن كل نص ينتمى إلى الداتا يتم تمثيله بجدول طوله 100 ألف و كل خانة تقابل كلمة من قائمة المفردات إذا ظهرت هذه الكلمة في النص فإن خانتها تحمل الرقم 1 و إلا 0. الصورة 1 مثال عن هذه الطريقة بإستخدام (CountVectorizer). لدينا ثلاث...